1 相关概念及简单分析
在这一部分,我将会提及相关的概念比如进程,进程空间等,同时也对 fork 系统调用过程进行简单的文字描述。
1.1 进程
操作系统是在计算机硬件和应用程序或者用户程序之间的一个软件层,它通过对硬件资源的抽象,对应用程序隐藏了复杂的硬件资源,状态及操作,同时也隔离了应用程序和硬件资源,防止应用软件随意地操作硬件而带来的安全隐患。操作系统为应用程序提供了几种重要的抽象概念,进程就是操作系统中最基础的抽象概念之一。
通常情况下,我们认为进程是一个程序(program)的运行实例。当一个程序存放在储存介质上的时候,它只是一个指令,数据及其组织形式的描述。操作系统可以将一个程序加载到内存中以一个进程的形式运行起来,这就是这个程序的一个运行实例。所以我们也是可以多次加载一个程序到内存中,形成该程序的多个独立的运行实例。一个进程的内容不单只是程序的执行指令,还包括了诸如打开的文件,等待的信号,内部内核数据,处理器状态,内存地址空间及内存映射等等的资源。
在早期的分时系统和面向进程的操作系统(比如早期的Unix和Linux)中,进程被认为是运行的基本单位。而在面向线程的操作系统(比如Linux2.6或更高版本)中,进程是资源分配的基本单位,而线程才是运行的基本单位。进程是线程的容器,而一个进程中会有一个或多个线程。实际上,在Linux中,对线程和进程有着特别的统一实现,线程只是一种特别的进程。这在下面的分析中将会提及。
1.2 进程空间
在进程被创建的时候,操作系统同时也给这个进程创建了一个独立的虚拟内存地址空间。这个虚拟内存地址空间使得一个进程存在着它独自使用着所有的内存资源的错觉,而且这也是该进程独立的,完全不受其他进程的干扰,所以这也使得各个进程区分开来。虽然对于一个进程而言,它拥有着很大的一个虚拟内存地址空间,但是这并不意味着每个进程实际上都拥有这么大物理内存。只有在真正使用某一部分内存空间的时候,这一部分虚拟内存才会被映射到物理内存上。此外,一个进程也不是可以访问或者修改这个虚拟内存地址空间的所有地址的。一个典型的进程内存地址空间会被分为 stack,heap,text,data,bss 等多个段,如下图(来自 Unix 高级环境编程)所示,这是一个进程在Intel x86架构机器上面的进程空间的逻辑表示:
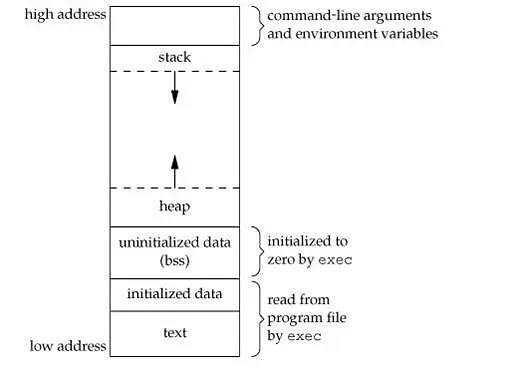
从上图可以看到,从低地址到高地址,有:
- text 段,主要保存着程序的代码对应的机器指令,这也将会是 CPU 所将要执行的机器指令的集合。text 段是可共享的,所以对于经常执行的程序只需保留一份 text 段的拷贝在内存中就可以了。特别地,text 段是只读的,进程无法对 text 段进行修改,这样可以防止一个进程意外地修改它自己的指令。
- data 段,包含着程序已经被初始化的变量。
- bss 段,在这个段中的未初始化变量在程序开始运行之前将会被内核初始化为0或者控指针。
- heap 段,用户程序动态的内存分配将会在这里进行。
- stack 段,每次一个函数被调用,函数的返回地址和调用者函数的上下文比如一些寄存器变量将会保存在这里。同时,这个被调用的函数将会为它的临时变量在这里分配一定内存空间。
- 在 stack 之上是命令行参数和一些环境变量。
- 更高的空间是内核空间,一般的进程都是不被允许访问的。
此外,stack 和 heap 段的增长方式是不同的,stack 段的内存是从高地址向低地址增长的,而 heap 段是从低地址向高地址增长的。一般情况下,stack 段的大小是有限制的,而 heap 段的大小是没有限制的,可以一直增长到整个系统的极限。在 stack 和 heap 之间是非常巨大的一个空间。
1.3 进程描述符
在 Linux 操作系统中,每个进程被创建的时候,内核会给这个进程分配一个进程描述符结构。进程描述符在一般的操作系统概念中也被称为 PCB ,也就是进程控制块。这个进程描述符保存了这个进程的状态,标识符,打开的文件,等待的信号,文件系统等待的资源信息。每个进程描述符都表示了独立的一个进程,而在系统中,每个进程的进程描述都加入到一个双向循环的任务队列中,由操作系统进行进程的调度,决定哪个进程可以占用 CPU ,哪个进程应该让出 CPU 。Linux 中的进程描述符是一个 task_struct 类型的结构体。在 Linux 中,一个进程的进程描述符结构如下图所示:
 )
)
task_struct 是一个相当大的数据结构,同时里面也指向了其他类型的数据结构,比如 thread_info,指向的是这个进程的线程信息; mm_struct 指向了这个进程的内存结构; file_struct 指向了这个进程打开的进程描述符结构,等等。task_struct 是一个复杂的数据结构,我们将会在下面对其进行更详细的分析。
1.4 系统调用
操作系统内核的代码运行在内核空间中,而应用程序或者我们平时所写的程序是运行在用户空间中的。操作系统对内核空间有相关的限制和保护,以免操作系统内核的空间受到用户应用程序的修改。也就是说只有内核才具有访问内核空间的权限,而应用程序是无法直接访问内核空间的。结合虚拟内存空间和进程空间,我们可以知道,内核空间的页表是常驻在内存中,不会被替换出去的。
我们上面提到,操作系统将硬件资源和应用程序隔离开来,那应用程序如果需要操作一些硬件或者获取一些资源如何实现?答案是内核提供了一系列的服务比如 IO 或者进程管理等给应用程序调用,也就是通过系统调用( system call )。如下图:
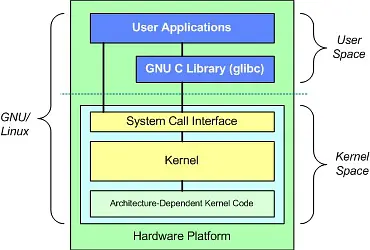
系统调用实际上就是函数调用,也是一系列的指令的集合。和普通的应用程序不同,系统调用是运行在内核空间的。当应用程序调用系统调用的时候,将会从用户空间切换到内核空间运行内核的代码。不同的架构实现内核调用的方式不同,在 i386 架构上,运行在用户空间的应用程序如果需要调用相关的系统调用,可以首先把系统调用编号和参数存放在相关的寄存器中,然后使用0x80这个值来执行软中断 int 。软中断发生之后,内核根据寄存器中的系统调用编号去执行相关的系统调用指令。
正如上面的图所展示的,应用程序可以直接通过系统调用接口调用内核提供的系统调用,也可以通过调用一些 C 库函数,而这些 C 库函数实际上是通过系统调用接口调用相关的系统调用。C 库函数有些在调用系统调用前后做一些特别的处理,但也有些函数只是单纯地对系统调用做了一层包装。
1.5 fork 系统调用
fork 系统调用是 Linux 中提供的众多系统调用中的一个,是2号系统调用。在 Linux 中,需要一种机制来创建新的进程,而 fork 就是 Linux 中提供的一个从旧的进程中创建新的进程的方法。我们在编程中,一般是调用 C 库的 fork 函数,而这个 fork 函数则是直接包装了 fork 系统调用的一个函数。fork 函数的效果是对当前进程进行复制,然后创建一个新的进程。旧进程和新进程之间是父子关系,父子进程共享了同一个 text 段,并且父子进程被创建后会从 fork 函数调用点下一个指令继续执行。fork 函数有着一次调用,两次返回的特点。在父进程中,fork 调用将会返回子进程的 PID ,而在子进程中,fork 调用返回的是0。之所以这样处理是因为进程描述符中保存着父进程的 PID ,所以子进程可以通过 getpid 来获取父进程的 PID,而进程描述符中却没有保存子进程的 PID 。
fork系统调用的调用过程简单描述如下:
- 首先是开始,父进程调用 fork ,因为这是一个系统调用,所以会导致 int 软中断,进入内核空间;
- 内核根据系统调用号,调用 sys_fork 系统调用,而 sys_fork 系统调用则是通过 clone 系统调用实现的,会调用 clone 系统调用;
- clone 系统调用的参数有一系列的标志用来标明父子进程之间将要共享的内容,这些内容包括虚拟内存空间,文件系统,文件描述符等。而对于 fork 来说,它调用 clone 系统调用的时候只是给 clone 一个 SIGCHLD 的标志,这表示子进程结束后将会给父进程一个 SIGCHLD 信号;
- 在 clone 函数中,将会调用 do_fork,这个函数是 fork 的主要执行部分。在 do_fork 中,首先做一些错误检查工作和准备复制父进程的初始化工作。然后 do_fork 函数调用 copy_process。
- copy_process 是对父进程的内核状态和相关的资源进行复制的主要函数。然后 copy_process 会调用 copy_thread 函数,复制父进程的执行状态,包括相关寄存器的值,指令指针和建立相关的栈;
- copy_thread 中还干了一件事,就是把0值写入到寄存器中,然后将指令指针指向一个汇编函数 ret_from_fork 。所以在子进程运行的时候,虽然代码和父进程的代码是一致的,但是还是有些区别。在 copy_thread 完毕后,没有返回到 do_fork ,而是跳到 ret_from_fork ,进行一些清理工作,然后退出到用户空间。用户空间函数可以通过寄存器中的值得到 fork 系统调用的返回值为0。
- copy_process 将会返回一个指向子进程的指针。然后回到 do_fork 函数,当 copy_process 函数成功返回的时候,子进程被唤醒,然后加入到进程调度队列中。此外,do_fork 将会返回子进程 的 PID;
在 Linux 中,创建一个新的进程的方式有三种,分别是 fork , vfork 和 clone。fork 是通过 clone 来实现的,而 vfork 和 clone 又是都通过 do_fork 函数来进行接下来的操作。
2 相关源码分析
本部分内容主要是对相关的具体源码进行分析,使用的 Linux 内核源码版本为3.6.11。被分析的源码并不是全部的相关源码,只是相关源码的一些重要部分。
2.1 进程描述符
在 Linux 中,进程描述符是一个 task_struct 类型的数据结构,这个数据结构的定义是在 Linux 源码的 include/linux/sched.h 中。
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack;
atomic_t usage;
unsigned int flags; /* per process flags, defined below */
unsigned int ptrace;
...
task_struct中 存放着一个进程的状态 state。进程的状态主要有五种,同时也是在 sched.h 中定义的:
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define __TASK_STOPPED 4
#define __TASK_TRACED 8
TASK_RUNNING:表示该进程是可以运行的,有可能是正在运行或者处于一个运行队列中等待运行。
TASK_INTERRUPTIBLE:进程正在休眠,或者说是被阻塞,等待一写条件成立,然后就会被唤醒,进入 TASK_RUNNING 状态。
TASK_UNINTERRUPTIBLE:和 TASK_INTERRUPTIBLE 状态一样,区别在于处于这个状态的进程不会对信号做出反应也不会转换到 TASK_RUNNING 状态。一般在进程不能受干扰或者等待的事件很快就会出现的情况下才会出现这种状态。
__TASK_STOPPED:进程的执行已经停止了,进程没有在运行也不能够运行。在进程接收到 SIGSTOP,SIGTSTP,SGITTIN 或者 SIGTOU 信号的时候就会进入这个状态。
__TASK_TRACED:该进程正在被其他进程跟踪运行,比如被 ptrace 跟踪中。
...
int prio, static_prio, normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
...
unsigned int policy;
这一部分是有关于进程调度信息的内容,调度程序利用这部分的信息决定哪一个进程最应该运行,并结合进程的状态信息保证系统进程调度的公平及高效。其中 prio , static_prio , normal_prio 分别表示了进程的动态优先级,静态优先级,普通优先级。rt_priority 表示进程的实时优先级,而 sched_class 则表示调度的类。se 和 rt 表示的都是调度实体,一个用于普通进程,一个用于实时进程。policy 则指出了进程的调度策略,进程的调度策略也是在 include/linux/sched.h 中定义的,如下:
/*
* Scheduling policies
*/
#define SCHED_NORMAL 0
#define SCHED_FIFO 1
#define SCHED_RR 2
#define SCHED_BATCH 3
/* SCHED_ISO: reserved but not implemented yet */
#define SCHED_IDLE 5
也就是有这几种调度策略:
- SCHED_NORMAL,用于普通进程;
- SCHED_FIFO,先来先服务;
- SCHED_RR,时间片轮转调度;
- SCHED_BATCH,用于非交互的处理器消耗型进程;
- SCHED_IDLE,主要是在系统负载低的时候使用。
一个进程还包括了各种的标识符,用来标识某一个特定的进程,同时也用来标识这个进程所属的进程组。如下:
...
pid_t pid;
pid_t tgid;
...
同时,在 task_struct 中也定义了一些特别指向其他进程的指针。
...
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->real_parent->pid)
*/
struct task_struct __rcu *real_parent; /* real parent process */
struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */
/*
* children/sibling forms the list of my natural children
*/
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct task_struct *group_leader; /* threadgroup leader */
...
正如上面这段代码中的注释所表示的,real_parent 指向本进程真正的父进程,也就是原始的父进程,而 parent 则指向了接收 SIGCHLD 信号的进程,如果一个进程被托孤给另外一个进程,比如 init 进程,那 init 进程将会是这个进程的 parent ,但不是原始进程。childern 则是一个本进程的子进程列表,sibling 是本进程的父进程的子进程列表。而 group_leader 指针指向的是线程组的领头进程。
...
cputime_t utime, stime, utimescaled, stimescaled;
cputime_t gtime;
...
unsigned long nvcsw, nivcsw; /* context switch counts */
struct timespec start_time; /* monotonic time */
struct timespec real_start_time; /* boot based time */
/* mm fault and swap info: this can arguably be seen as either
mm-specific or thread-specific */
unsigned long min_flt, maj_flt;
struct task_cputime cputime_expires;
struct list_head cpu_timers[3];
...
一个进程,从创建到结束,这是它的生命周期。在进程生命周期中有许多与时间相关的内容,这些内容也包括在进程描述符中了。如上代码,我们可以看到有好几个数据类型为 cputime 的成员。utime 和 stime 分别表示进程在用户态下使用 CPU 的时间和在内核态下使用 CPU 的时间,这两个成员的单位是一个 click 。而 utimescaled 和 stimescaled 同样也是分别表示进程在这两种状态下使用 CPU 的时间,只不过单位是处理器的频率。 gtime 表示的是虚拟处理器的运行时间。start_time 和 real_start_time 表示的都是进程的创建时间,real_start_time 包括了进程睡眠的时间。cputime_expires 表示的是进程或者进程组被跟踪的 CPU 时间,对应着 cpu_timers 的三个值。
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
如上,进程描述符还保存了进程的文件系统相关的信息,比如上面的两个成员,fs 表示的是进程与文件系统的关联,包括当前目录和根目录,而 files 则是指向进程打开的文件
在进程描述符中,还有很多重要的信息,比如虚拟内存信息,进程间通信机制, pipe ,还有一些中断和锁的机制等等。更具体的内容可以直接翻阅 Linux 源码中 task_struct 的定义。
2.2 fork 系统调用
fork 系统调用实际上调用的是 sys_fork 这个函数,在 Linux 中,sys_fork 是一个定义在 arch/alpha/kernel/entry.S 中的汇编函数。
.align 4
.globl sys_fork
.ent sys_fork
sys_fork:
.prologue 0
mov $sp, $21
bsr $1, do_switch_stack
bis $31, SIGCHLD, $16
mov $31, $17
mov $31, $18
mov $31, $19
mov $31, $20
jsr $26, alpha_clone
bsr $1, undo_switch_stack
ret
.end sys_fork
如上,可以看到在sys_fork中,将相关的标志 SIGCHLD 等参数压栈后,然后就专跳到 alpga_clone 函数中执行。
2.3 alpha_clone
alpha_clone 函数的定义在源码目录中的 arch/alpah/kernel/process.c ,具体代码如下:
/*
* "alpha_clone()".. By the time we get here, the
* non-volatile registers have also been saved on the
* stack. We do some ugly pointer stuff here.. (see
* also copy_thread)
*
* Notice that "fork()" is implemented in terms of clone,
* with parameters (SIGCHLD, 0).
*/
int
alpha_clone(unsigned long clone_flags, unsigned long usp,
int __user *parent_tid, int __user *child_tid,
unsigned long tls_value, struct pt_regs *regs)
{
if (!usp)
usp = rdusp();
return do_fork(clone_flags, usp, regs, 0, parent_tid, child_tid);
}
正如注释所提到的,在执行 alpah_clone 函数之前已经将寄存器的相关的值保存到栈中了,在此函数中将会根据相关的调用 do_fork 函数。
2.4 do_fork
创建一个新的进程的大部分工作是在 do_fork 中完成的,主要是根据标志参数对父进程的相关资源进行复制,得到一个新的进程。do_fork 函数定义在源码目录的 kernel/fork.c 中。
/*
* Ok, this is the main fork-routine.
*
* It copies the process, and if successful kick-starts
* it and waits for it to finish using the VM if required.
*/
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
...
首先我们来了解一下 do_fork 函数的参数。clone_flags 是一个标志集合,主要是用来控制复制父进程的资源。clone_flags 的低位保存了子进程结束时发给父进程的信号号码,而高位则保存了其他的各种常数。这些常数也是定义在 include/linux/sched.h 中的,如下:
/*
* cloning flags:
*/
#define CSIGNAL 0x000000ff /* signal mask to be sent at exit */
#define CLONE_VM 0x00000100 /* set if VM shared between processes */
#define CLONE_FS 0x00000200 /* set if fs info shared between processes */
#define CLONE_FILES 0x00000400 /* set if open files shared between processes */
#define CLONE_SIGHAND 0x00000800 /* set if signal handlers and blocked signals shared */
#define CLONE_PTRACE 0x00002000 /* set if we want to let tracing continue on the child too */
#define CLONE_VFORK 0x00004000 /* set if the parent wants the child to wake it up on mm_release */
#define CLONE_PARENT 0x00008000 /* set if we want to have the same parent as the cloner */
#define CLONE_THREAD 0x00010000 /* Same thread group? */
#define CLONE_NEWNS 0x00020000 /* New namespace group? */
#define CLONE_SYSVSEM 0x00040000 /* share system V SEM_UNDO semantics */
#define CLONE_SETTLS 0x00080000 /* create a new TLS for the child */
#define CLONE_PARENT_SETTID 0x00100000 /* set the TID in the parent */
#define CLONE_CHILD_CLEARTID 0x00200000 /* clear the TID in the child */
#define CLONE_DETACHED 0x00400000 /* Unused, ignored */
#define CLONE_UNTRACED 0x00800000 /* set if the tracing process can't force CLONE_PTRACE on this clone */
#define CLONE_CHILD_SETTID 0x01000000 /* set the TID in the child */
- CLONE_VM 表示在父子进程间共享 VM ;
- CLONE_FS 表示在父子进程间共享文件系统信息,包括工作目录等;
- CLONE_FILES 表示在父子进程间共享打开的文件;
- CLONE_SIGHAND 表示在父子进程间共享信号的处理函数;
- CLONE_PTRACE 表示如果父进程被跟踪,子进程也被跟踪;
- CLONE_VFORK 在 vfork 的时候使用;
- CLONE_PARENT 表示和复制的进程有同样的父进程;
- CLONE_THREAD 表示同一个线程组;
之前提到过,在 Linux 中,线程的实现是和进程统一的,就是说,在 Linux 中,进程和线程的结构都是 task_struct 。区别在于,多个线程会共享一个进程的资源,包括虚拟地址空间,文件系统,打开的文件和信号处理函数。线程的创建和一般的进程的创建差不多,区别在于调用 clone 系统调用时,需要通过传入相关的标志参数指定要共享的特定资源。通常是这样的:clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0)。
do_fork 函数的参数 stack_start 表示的是用户状态下,栈的起始地址。regs 是一个指向寄存器集合的指针,在其中保存了调用的参数。当进程从用户态切换到内核态的时候,该结构体保存通用寄存器中的值,并存放到内核态的堆栈中。stack_size 是用户态下的栈大小,一般是不必要的,设置为0。而 parent_tidptr 和 child_tidptr 则分别是指向用户态下父进程和和子进程的 TID 的指针。
/*
* Do some preliminary argument and permissions checking before we
* actually start allocating stuff
*/
if (clone_flags & CLONE_NEWUSER) {
if (clone_flags & CLONE_THREAD)
return -EINVAL;
/* hopefully this check will go away when userns support is
* complete
*/
if (!capable(CAP_SYS_ADMIN) || !capable(CAP_SETUID) ||
!capable(CAP_SETGID))
return -EPERM;
}
上面这段代码主要是对参数的 clone_flags 组合的正确性进行检查,因为标志需要遵循一定的规则,如果不符合,则返回错误代码。此外还需要对权限进行检查。
/*
* Determine whether and which event to report to ptracer. When
* called from kernel_thread or CLONE_UNTRACED is explicitly
* requested, no event is reported; otherwise, report if the event
* for the type of forking is enabled.
*/
if (likely(user_mode(regs)) && !(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if ((clone_flags & CSIGNAL) != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
决定报告给 ptracer 的事件,如果是从 kernel_thread 中调用后者参数中指明了 CLONE_UNTRACED ,将不会有任何的事件被报告。否则,根据创建进程的类型 clone ,fork 或者 vfork 报告支持的事件。
然后 do_fork 将会调用 copy_process,如下:
p = copy_process(clone_flags, stack_start, regs, stack_size,
child_tidptr, NULL, trace);
2.5 copy_process
copy_process 函数也是定义在源码目录的 kernel/fork.c 中,这个函数将会复制父进程,作为新创建的一个进程,也就是子进程。copy_process 会复制寄存器,然后也根据每个 clone 的标志,复制父进程环境的相关内容或者也可能共享父进程的内容。
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
struct task_struct *p;
int cgroup_callbacks_done = 0;
从 copy_process 函数的参数来看,do_fork 函数的所有参数也都被传入到这个函数中了,此外,后面还有一个参数 trace 标识是否对子进程进行跟踪和参数 pid 。在函数的开始,定义了一个未初始化的 task_struct 类型的指针 p。
在 copy_process 这里也对 clone 标志的有效性进行了检查,如下:
if ((clone_flags & (CLONE_NEWNS|CLONE_FS)) == (CLONE_NEWNS|CLONE_FS))
return ERR_PTR(-EINVAL);
if ((clone_flags & CLONE_THREAD) && !(clone_flags & CLONE_SIGHAND))
return ERR_PTR(-EINVAL);
if ((clone_flags & CLONE_SIGHAND) && !(clone_flags & CLONE_VM))
return ERR_PTR(-EINVAL);
if ((clone_flags & CLONE_PARENT) &&
current->signal->flags & SIGNAL_UNKILLABLE)
return ERR_PTR(-EINVAL);
在 copy_process 函数中同样也进行了一系列的函数调用。比如 dup_task_struct 函数:
p = dup_task_struct(current);
if (!p)
goto fork_out;
dup_task_struct 函数将会为心的进程创建一个新的内核栈,thread_info 结构和 task_struct 结构。thread_info 结构是一个比较简单的数据结构,主要保存了进程的 task_struct 还有其他一些比较底层的内容。新值和当前进程的值是一致,所以可以说此时父子进程的进程描述符是一致的。current 实际上是一个获取当前进程描述符的宏定义函数,返回当前调用系统调用的进程描述符,也就是父进程。
if (atomic_read(&p->real_cred->user->processes) >=
task_rlimit(p, RLIMIT_NPROC)) {
if (!capable(CAP_SYS_ADMIN) && !capable(CAP_SYS_RESOURCE) &&
p->real_cred->user != INIT_USER)
goto bad_fork_free;
}
在创建新进程的相关核心数据结构后,将会对这个新的进程进行检查,看是否超出了当前用户的进程数限制。如果超出限制了,并且没有相关的权限,也不是 init 用户,将会转跳到相关的失败处理指令处。
p->did_exec = 0;
delayacct_tsk_init(p); /* Must remain after dup_task_struct() */
copy_flags(clone_flags, p);
INIT_LIST_HEAD(&p->children);
INIT_LIST_HEAD(&p->sibling);
rcu_copy_process(p);
p->vfork_done = NULL;
spin_lock_init(&p->alloc_lock);
init_sigpending(&p->pending);
这段代码首先将进程描述符p的did_exec值设置为0,以保证这个新创建的进程不会被运行。因为子进程和父进程实际上还是有区别的,所以,接着将会将子进程的进程描述符的部分内容清除掉并设置为初始的值。如上,新创建的进程的描述符中 children ,sibling 和等待的信号等值都被初始化了。然后,这段代码还调用了 copy_flags 函数,copy_flags 函数如下:
static void copy_flags(unsigned long clone_flags, struct task_struct *p)
{
unsigned long new_flags = p->flags;
new_flags &= ~(PF_SUPERPRIV | PF_WQ_WORKER);
new_flags |= PF_FORKNOEXEC;
p->flags = new_flags;
}
copy_flags 函数将会更新这个新创建的子进程的标志,主要是清除 PF_SUPERPRIV 标志,这个标志表示一个进程是否使用超级用户权限。然后还有就是设置 PF_FORKNOEXEC 标志,表示这个进程还没有执行过 exec 函数。
retval = perf_event_init_task(p);
if (retval)
goto bad_fork_cleanup_policy;
retval = audit_alloc(p);
if (retval)
goto bad_fork_cleanup_policy;
/* copy all the process information */
retval = copy_semundo(clone_flags, p);
if (retval)
goto bad_fork_cleanup_audit;
retval = copy_files(clone_flags, p);
if (retval)
goto bad_fork_cleanup_semundo;
retval = copy_fs(clone_flags, p);
if (retval)
goto bad_fork_cleanup_files;
retval = copy_sighand(clone_flags, p);
if (retval)
goto bad_fork_cleanup_fs;
retval = copy_signal(clone_flags, p);
if (retval)
goto bad_fork_cleanup_sighand;
retval = copy_mm(clone_flags, p);
if (retval)
goto bad_fork_cleanup_signal;
retval = copy_namespaces(clone_flags, p);
if (retval)
goto bad_fork_cleanup_mm;
retval = copy_io(clone_flags, p);
if (retval)
goto bad_fork_cleanup_namespaces;
retval = copy_thread(clone_flags, stack_start, stack_size, p, regs);
if (retval)
goto bad_fork_cleanup_io;
上面代码就是根据 clone_flags 集合中的值,共享或者复制父进程打开的文件,文件系统信息,信号处理函数,进程地址空间,命名空间等资源。这些资源通常情况下在一个进程内的多个线程才会共享,对于我们现在分析的 fork 系统调用来说,对于这些资源都会复制一份到子进程。
if (pid != &init_struct_pid) {
retval = -ENOMEM;
pid = alloc_pid(p->nsproxy->pid_ns);
if (!pid)
goto bad_fork_cleanup_io;
}
因为在 do_fork 函数中调用 copy_process 函数的时候,参数 pid 的值为 NULL,所以此时新建进程的 PID 其实还没有被分配。所以接下来的就是要给子进程分配一个 PID。
最后,copy_process 函数做了一些清理工作,并且返回一个指向新建的子进程的指针给 do_fork 函数。
2.6 回到 do_fork
if (!IS_ERR(p)) {
...
wake_up_new_task(p);
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event(trace, nr);
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event(PTRACE_EVENT_VFORK_DONE, nr);
}
回到 do_fork 函数中,如果 copy_process 函数执行成功,没有错误,那么将会唤醒新创建的子进程,让子进程运行。自此,fork 函数调用成功执行。
3 具体例程分析
在这一部分,我将会结合相关的具体例程,进行一些简单的分析。
3.1 例程代码
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#define LEN 1024 * 1024
int main(int argc, char **argv)
{
pid_t pid;
int num = 10, i;
char *p;
p = malloc(LEN * sizeof(char));
pid = fork();
if (pid > 0) {
/*parent process.*/
printf("parent %d process get %d!It stores in %x.\n",
getpid(), num, &num);
printf("parent have a piece of memory start from %x.\n",
p);
} else {
/*child process.*/
printf("child %d process get %d!It stores in %x.\n",
getpid(), num, &num);
printf("child have a piece of memory start from %x.\n",
p);
}
while(1){}
return 0;
}
这个程序只是简单地调用了一次 fork ,创建了一个子进程,然后分别在父子进程中查看申请的一块内存的起始地址。此外还添加了一个 while 死循环,方便父子进程的进程控制块进行查看。
3.2 相关分析
这个程序执行的结果截图如下:
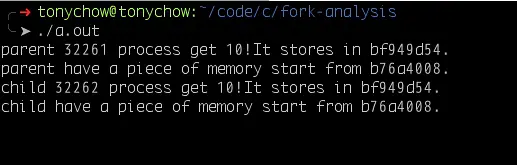
可以看到,通过对 pid 的值检测,我们让父子进程执行了不同的代码。
通过 ps aux | grep a.out 指令,我们可以得到父子进程的 PID:
$ps aux | grep a.out
tonychow 32261 93.8 0.0 3056 272 pts/1 R+ 10:57 4:11 ./a.out
tonychow 32262 93.3 0.0 3056 52 pts/1 R+ 10:57 4:10 ./a.out
每个进程,在其生命周期期间,都会在 /proc/ 进程号 目录中保存相关的进程内容,我们可以查看里面的内容对这个进程进行分析。根据上面的运行结果,我们可以通过 ls -al /proc/32261 这个指令来查看该文件夹中的内容:
$ls -al /proc/32261
总用量 0
dr-xr-xr-x 8 tonychow tonychow 0 6月 27 10:59 .
dr-xr-xr-x 267 root root 0 5月 31 12:18 ..
dr-xr-xr-x 2 tonychow tonychow 0 6月 27 11:06 attr
-rw-r--r-- 1 tonychow tonychow 0 6月 27 11:06 autogroup
-r-------- 1 tonychow tonychow 0 6月 27 11:06 auxv
-r--r--r-- 1 tonychow tonychow 0 6月 27 11:06 cgroup
--w------- 1 tonychow tonychow 0 6月 27 11:06 clear_refs
-r--r--r-- 1 tonychow tonychow 0 6月 27 11:02 cmdline
-rw-r--r-- 1 tonychow tonychow 0 6月 27 11:06 comm
-rw-r--r-- 1 tonychow tonychow 0 6月 27 11:06 coredump_filter
-r--r--r-- 1 tonychow tonychow 0 6月 27 11:06 cpuset
lrwxrwxrwx 1 tonychow tonychow 0 6月 27 11:06 cwd -> /home/tonychow/code/c/fork-analysis
-r-------- 1 tonychow tonychow 0 6月 27 11:03 environ
lrwxrwxrwx 1 tonychow tonychow 0 6月 27 11:06 exe -> /home/tonychow/code/c/fork-analysis/a.out
dr-x------ 2 tonychow tonychow 0 6月 27 10:59 fd
dr-x------ 2 tonychow tonychow 0 6月 27 11:06 fdinfo
-r-------- 1 tonychow tonychow 0 6月 27 11:06 io
-r--r--r-- 1 tonychow tonychow 0 6月 27 11:06 latency
-r--r--r-- 1 tonychow tonychow 0 6月 27 11:06 limits
-rw-r--r-- 1 tonychow tonychow 0 6月 27 11:06 loginuid
-r--r--r-- 1 tonychow tonychow 0 6月 27 11:06 maps
-rw------- 1 tonychow tonychow 0 6月 27 11:06 mem
-r--r--r-- 1 tonychow tonychow 0 6月 27 11:06 mountinfo
-r--r--r-- 1 tonychow tonychow 0 6月 27 11:06 mounts
-r-------- 1 tonychow tonychow 0 6月 27 11:06 mountstats
dr-xr-xr-x 6 tonychow tonychow 0 6月 27 11:06 net
dr-x--x--x 2 tonychow tonychow 0 6月 27 11:06 ns
-rw-r--r-- 1 tonychow tonychow 0 6月 27 11:06 oom_adj
-r--r--r-- 1 tonychow tonychow 0 6月 27 11:06 oom_score
-rw-r--r-- 1 tonychow tonychow 0 6月 27 11:06 oom_score_adj
-r--r--r-- 1 tonychow tonychow 0 6月 27 11:06 pagemap
-r--r--r-- 1 tonychow tonychow 0 6月 27 11:06 personality
lrwxrwxrwx 1 tonychow tonychow 0 6月 27 11:06 root -> /
-rw-r--r-- 1 tonychow tonychow 0 6月 27 11:06 sched
-r--r--r-- 1 tonychow tonychow 0 6月 27 11:06 schedstat
-r--r--r-- 1 tonychow tonychow 0 6月 27 11:06 sessionid
-r--r--r-- 1 tonychow tonychow 0 6月 27 11:06 smaps
-r--r--r-- 1 tonychow tonychow 0 6月 27 11:06 stack
-r--r--r-- 1 tonychow tonychow 0 6月 27 11:02 stat
-r--r--r-- 1 tonychow tonychow 0 6月 27 11:06 statm
-r--r--r-- 1 tonychow tonychow 0 6月 27 11:02 status
-r--r--r-- 1 tonychow tonychow 0 6月 27 11:06 syscall
dr-xr-xr-x 3 tonychow tonychow 0 6月 27 11:06 task
-r--r--r-- 1 tonychow tonychow 0 6月 27 11:06 wchan
从上面的结果可以看到列出了一堆的信息文件,包括状态,io,限制,文件,命名空间等等这些属于这个进程的一大堆资源。分别查看这两个进程的 status 信息:
$cat /proc/32261/status
Name: a.out
State: R (running)
Tgid: 32261
Pid: 32261
PPid: 12747
...
$cat /proc/32262/status
Name: a.out
State: R (running)
Tgid: 32262
Pid: 32262
PPid: 32261
...
从上面的结果可以看到,这两个进程都处于 running 状态,而进程32261是进程32262的父进程。接着查看一下内存映射信息:
$cat /proc/32261/maps
08048000-08049000 r-xp 00000000 fd:02 20979068 /home/tonychow/code/c/fork-analysis/a.out
08049000-0804a000 rw-p 00000000 fd:02 20979068 /home/tonychow/code/c/fork-analysis/a.out
4b94d000-4b96c000 r-xp 00000000 fd:01 793014 /usr/lib/ld-2.15.so
4b96c000-4b96d000 r--p 0001e000 fd:01 793014 /usr/lib/ld-2.15.so
4b96d000-4b96e000 rw-p 0001f000 fd:01 793014 /usr/lib/ld-2.15.so
4b970000-4bb1b000 r-xp 00000000 fd:01 809017 /usr/lib/libc-2.15.so
4bb1b000-4bb1c000 ---p 001ab000 fd:01 809017 /usr/lib/libc-2.15.so
4bb1c000-4bb1e000 r--p 001ab000 fd:01 809017 /usr/lib/libc-2.15.so
4bb1e000-4bb1f000 rw-p 001ad000 fd:01 809017 /usr/lib/libc-2.15.so
4bb1f000-4bb22000 rw-p 00000000 00:00 0
b76a4000-b77a6000 rw-p 00000000 00:00 0
b77be000-b77c0000 rw-p 00000000 00:00 0
b77c0000-b77c1000 r-xp 00000000 00:00 0 [vdso]
bf92a000-bf94b000 rw-p 00000000 00:00 0 [stack]
结合上面程序的输出,可以看到 int 的类型的变量 num 存放在栈中,而通过 malloc 得到的则是存放在堆中。
$ls -l /proc/32261/fd
总用量 0
lrwx------ 1 tonychow tonychow 64 6月 27 10:59 0 -> /dev/pts/1
lrwx------ 1 tonychow tonychow 64 6月 27 10:59 1 -> /dev/pts/1
lrwx------ 1 tonychow tonychow 64 6月 27 10:59 2 -> /dev/pts/1
查看下该进程的文件描述符,可以看到主要是有标准输出,标准输入和标准输出这三个。
$ cat /proc/32261/limits
limit soft limit hard limit units
max cpu time unlimited unlimited seconds
max file size unlimited unlimited bytes
max data size unlimited unlimited bytes
max stack size 8388608 unlimited bytes
max core file size 0 unlimited bytes
max resident set unlimited unlimited bytes
max processes 1024 31683 processes
max open files 1024 4096 files
max locked memory 65536 65536 bytes
max address space unlimited unlimited bytes
max file locks unlimited unlimited locks
max pending signals 31683 31683 signals
max msgqueue size 819200 819200 bytes
max nice priority 0 0
max realtime priority 0 0
max realtime timeout unlimited unlimited us
通过 cat /proc/32261/limits 命令我们可以看到系统对这个用户的一些资源限制,包括 CPU 时间,最大文件大小,最大栈大小,进程数,文件数,最大地址空间等等的资源。
4 总结
经过这次对 Linux 系统的 fork 系统调用的分析,主要有以下几点总结:
- fork 调用是 Linux 系统中很重要的一个创建进程的方式,系统级别的进程和线程都是通过 fork 系统调用来实现的,它的实现其实也依靠了 clone 系统调用;
- 在 Linux 系统中,一个进程内多个线程其实就是共享了父进程大部分资源的子进程,内核通过 clone_flags 来控制创建这种特别的进程;
- Linux 其实也是一个软件,但是它是一个复杂无比的软件。虽然从源码来说,不同的部分分得挺清楚,但是具体到一个个函数的执行,对于我们新手而言,如果没有注释,有时候真的很难知道一个函数的参数是什么意思。这时候就要依靠搜索引擎的力量了。
5 主要参考文献